Beyond “It Seems to Work”
Testing Generative AI applications is fundamentally different from testing traditional software. Methodologies designed for predictable, deterministic systems are ill-equipped to handle the non-deterministic nature of LLM-based apps. The core difficulty stems from two interconnected problems:- The Infinite Input Space: The range of possible user inputs is endless, making it impossible to write enough static test cases to cover every scenario.
- Non-Deterministic & “Fuzzy” Outputs: An LLM model can produce a wide variety of responses to the same prompt, and quality itself is often subjective.
“We are confident that at least 90% of user issues coming into our customer support chatbot will be resolved with a quality score of 8/10 or higher.”
“With a high degree of confidence, the median response time of our new AI-proposal generator will be lower than our 5-second SLO.”
Get Started
Start using SigmaEval in minutes with a quickstart guide.
How it Works
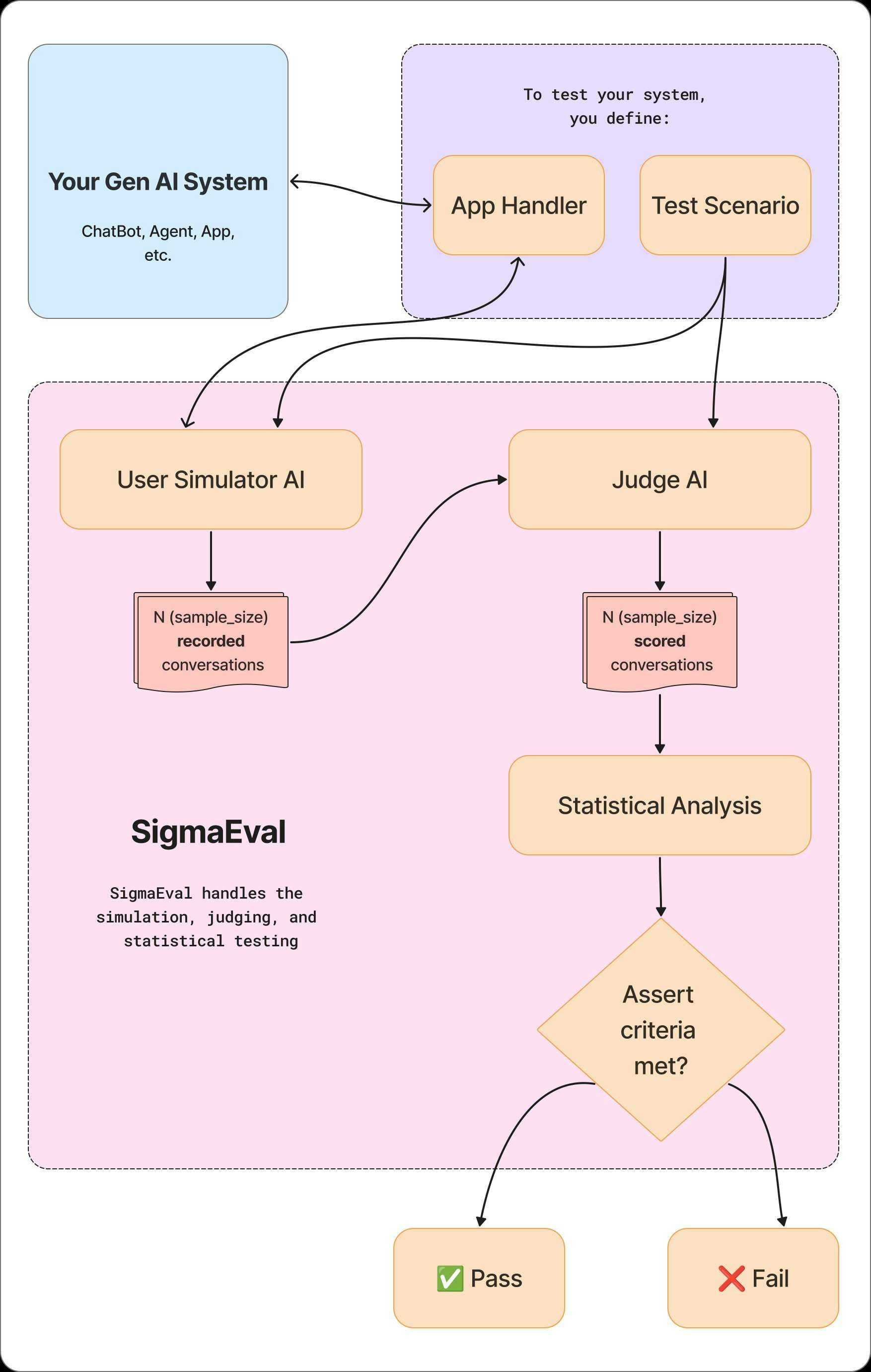
At its core, SigmaEval uses two AI agents to automate evaluation: an AI User Simulator that realistically tests your application, and an AI Judge that scores its performance. The process is as follows:1
Define 'Good'
You start by defining a test scenario in plain language, including the
user’s goal and a clear description of the successful outcome you expect.
This becomes your objective quality bar.
2
Simulate and Collect Data
The AI User Simulator acts as a test user, interacting with your
application based on your scenario. It runs these interactions many times to
collect a robust dataset of conversations.
3
Judge and Analyze
The AI Judge scores each conversation against your definition of
success. SigmaEval then applies statistical methods to these scores to
determine if your quality bar has been met with a specified level of
confidence.
Key Features
Statistical Evaluation
Perform comprehensive statistical analyses of your Gen AI applications with
confidence intervals and rigorous testing.
End-to-End Testing
Test all aspects of your Gen AI app performance, from response quality to
latency and reliability.
Pytest & Unittest Ready
Drop SigmaEval directly into your existing test suites. It’s fully
compatible with popular frameworks like Pytest and Unittest.
100+ LLM Providers
Support for over 100 LLM providers for the AI Judge and User Simulator.
Data-Driven Decisions
Move from intuition-based decisions to quantifiable, objective assessments
of your AI’s capabilities.
Resources
GitHub Repository
View the source code, contribute, and report issues.
PyPI Package
Install and view package details on PyPI.
Get Started
Get Started
Start using SigmaEval in minutes with a quickstart guide.